
AI算力演进驱动HBM需求爆发


海力士 HBM3 芯片, 数据来源:海力士官网,财通证券研究所
自2023年初以来,生成式人工智能(AI)模型因其不断的应用和商业化而受到极大关注。这些模型的发展推动了对人工智能基础设施的需求,尤其是在算力和通信领域。生成式AI模型,如大型语言模型GPT,需要大量高性能硬件(如GPU和TPU)、庞大的高质量数据集以及先进的软件算法。这些模型含有数十亿参数,需要比传统SOC更大的存储空间和内存访问能力。随着GPT等模型算力需求的增长,对芯片的速度和容量提出了更高的要求。在这个背景下,Chiplet技术在算力芯片领域的应用显得尤为重要,它不仅降低了大面积芯片的成本和提高了良率,还便于引入高速HBM存储,从而允许更多计算核心的集成。
作为全球知名的AI计算领导者,NVIDIA占据了全球约80%的算力芯片市场。2022年发布的H100 GPU芯片,结合了Chiplet技术和台积电4nm工艺,通过将HBM3显存子系统集成到芯片中,实现了超高的显存带宽和性能。NVIDIA最近推出的AI超级计算机DGX GH200结合了Arm架构的Grace CPU和Hopper架构的GPU,具备强大的存储和通信能力,特别适合于生成式AI模型的训练。
除了NVIDIA,AMD最新发布的MI300X GPU是公司迄今为止最先进的AI图形处理器,明确挑战NVIDIA的H100 GPU。这款基于Chiplet设计的加速器拥有多个基于3D堆叠的5nm和6nm小芯片,周围封装了大容量HBM3显存,拥有1530亿个晶体管,显存性能和容量均超过了NVIDIA的H100,非常适合于AI运算和适配大型语言模型。
随着GPU等AI芯片的发展,带宽需求不断增加,传统的GDDR5技术已无法满足高性能计算场景的需求。HBM通过重新调整内存的功耗效率,使每瓦带宽比GDDR5高出3倍以上,大大降低了功耗。这些AI芯片的兴起不仅促进了HBM等高传输能力存储技术的发展,而且成为存储巨头应对市场下行行情的重要增长点。

英伟达、AMD 目前主流 AI 训练芯片都采用 HBM 以增加带宽,来源:AMD、英伟达网站,国金证券研究所
解决内存瓶颈,HBM的优势与挑战?
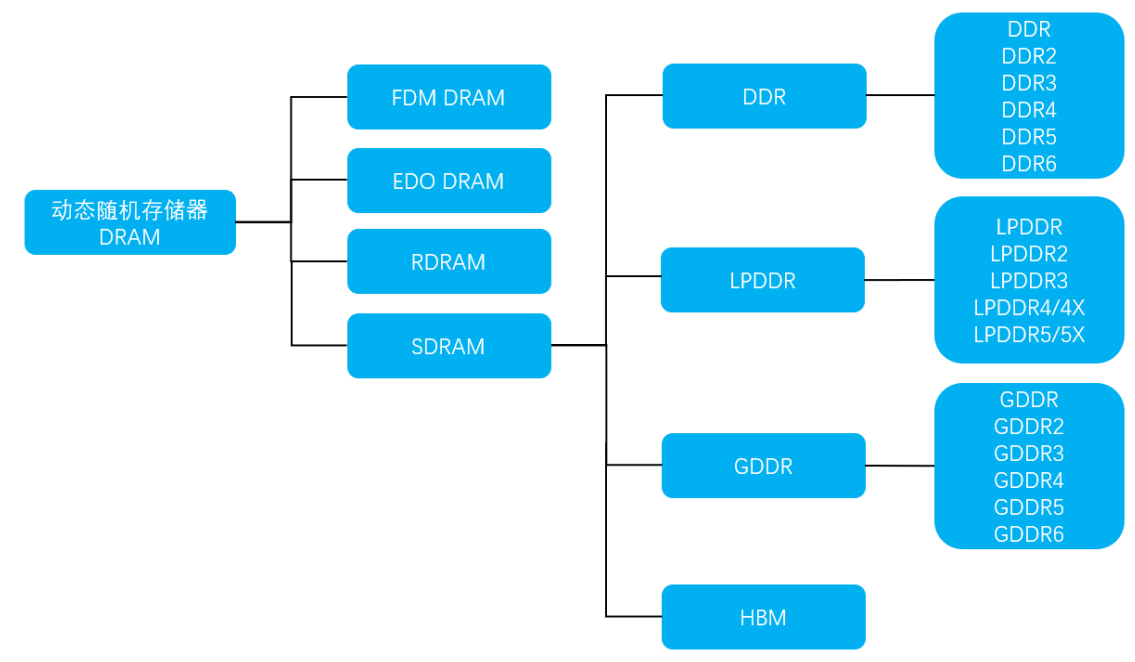
DRAM 分类结构图,资料来源:互联网公开信息整理,中原证券
HBM(High Bandwidth Memory)是一种高性能的3D DRAM技术,专门设计用于解决传统内存技术在带宽和容量方面的局限性。这种高带宽存储器通过使用TSV(Through-Silicon Vias)技术,将多个DRAM芯片垂直堆叠在一起,并与GPU或CPU紧密封装,从而实现了显著的性能提升。
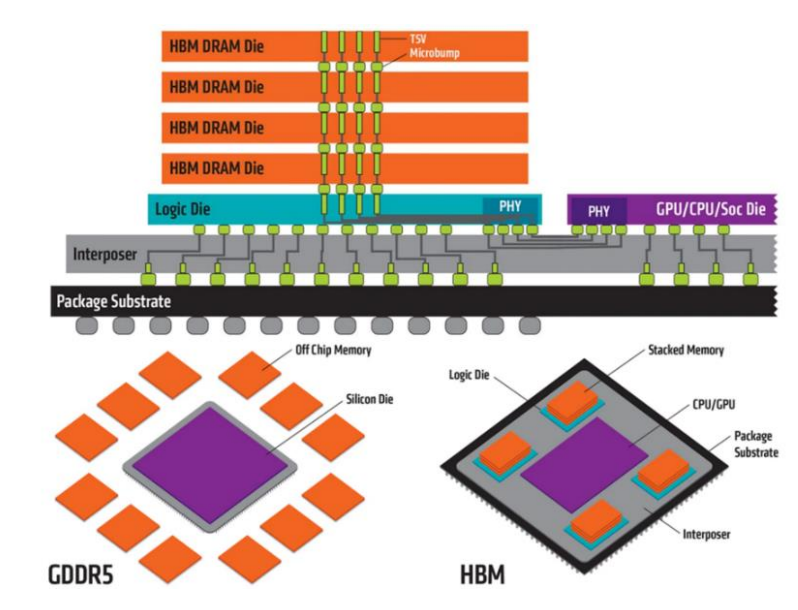
HBM 通过中介层(Interposer)与 GPU 连接, 资料来源:TrendForce,华安证券研究所
相对于其他类型的DRAM,HBM的主要优势在于其短外部导线长度,这意味着数据传输速度更快,能耗更低,因此被认为是最理想化的3D DRAM形式之一。这种设计使HBM能够突破传统内存技术的限制,尤其是在内存容量和带宽方面,从而克服了被称为“内存墙”的性能瓶颈。
HBM技术在提供大容量和高带宽方面具有显著优势。例如,最新的HBM3可以达到819GB/s的高带宽,这远远超过了传统的DDR4和GDDR6内存技术。这种显著的性能提升对于AI计算、区块链和数字货币挖矿等需要处理大量数据的应用场景至关重要。
除了高性能计算领域外,HBM还被广泛应用于其他硬件,如汽车存储器、GPU显存芯片、部分CPU内存芯片、边缘AI加速卡和Chiplets等。例如,在NVIDIA的A100加速卡和富岳超级计算机的A64FX芯片中均应用了HBM技术。随着异构计算和小芯片技术的发展,对高带宽内存的需求也在增长。
AI处理器架构方面的IO问题也是HBM技术发展的重要推动因素。随着AI模型变得更加复杂,算力需求增加,内存带宽成为了一个关键瓶颈。HBM通过晶片堆叠技术和硅联通层将处理器和存储器连接起来,提高了集成度和效率,降低了功耗,从而在一定程度上解决了IO瓶颈问题。
HBM的核心技术挑战在于TSV技术的应用,它通过在硅芯片内部形成通孔并将多个芯片垂直堆叠来实现。这种方法不仅减小了封装面积,而且允许在相同厚度下堆叠更多的芯片。随着对更高容量存储器的需求增加,未来可能需要12层甚至更多层的芯片堆叠技术。为了实现这一目标,需要减小芯片的厚度、缩小凸块电极的尺寸,并采用混合键合技术,去除芯片间的填充物,实现直接铜电极连接。
由于 HBM 较传统 GDDR 与 DRAM 具备更高的带宽,在数据流量不断提升的当下,除了当前的AI 芯片的相关应用以外,未来有望在其他各类逻辑芯片、通信行业交换机与路由器等都产生较广阔的应用,成为存储行业未来新的增长点。
价格上涨与需求激增,三巨头垄断HBM市场

2022-2026E HBM 市场规模预测情况,资料来源:TrendForce,中银证券测算
HBM的平均售价是DRAM的三倍以上,受到产能限制和生成式AI等应用的推动,价格一直上涨。根据TrendForce数据,高端AI服务器GPU已普遍采用HBM,预计2023年全球HBM需求量将年增近六成,达到2.9亿GB,2024年将再增长三成。预测从2023到2027年,HBM市场的复合年均增长率达到82%。根据DRAMexchange的数据,2022年7月31日8Gb DDR4合约价格为2.88美元,2023年同日价格为1.34美元。假设HBM价格为DDR4的5倍,2023年全球AI服务器存储市场规模预计为76亿美元,预计2026年能达到492.4亿美元,2023-2026年CAGR为86.4%。
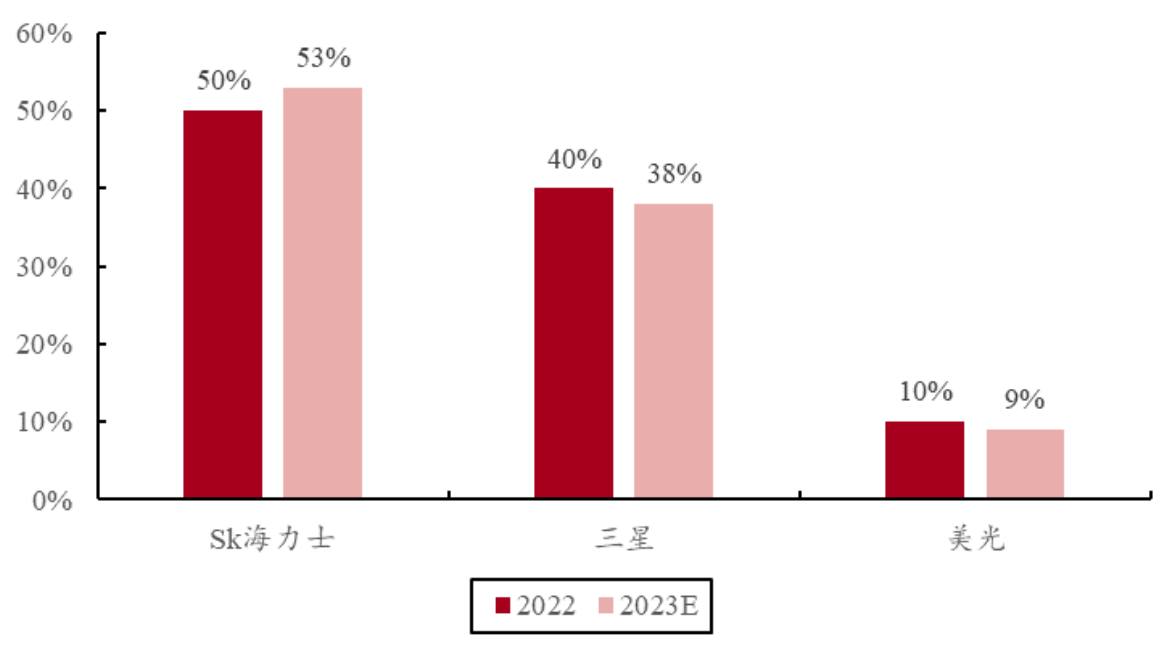
HBM 市占率预测,资料来源:TrendForce,中银证券
目前HBM市场主要由SK海力士、三星和美光所垄断。2022年,SK海力士占据了市场的50%,三星约40%,美光约10%。SK海力士和三星的市占率预计在2023-2024年间将会持平,达到约95%的总市场份额。美光则专注于开发HBM3e产品,但可能略有下滑。

HBM2014-2022 年发展历程,资料来源:SK 海力士官网,三星官网,美光官网,中银证券整理
SK海力士于2013年率先推出HBM1,2017年推出HBM2,2018年JEDEC推出HBM2E规范。2021年10月, SK海力士首创于并于2022年6月量产HBM3,三星也将于2023年末至2024年初量产。SK海力士被认为是目前唯一可以实现HBM3量产的厂商。他们最新开发的HBM3E数据传输速率提升了25%。三星和美光也积极布局HBM新产品,加速推动12层HBM内存的生产。美光的HBM3 Gen 2计划于2024年初量产,并在2022年宣布推出业界首款8层24GB HBM3 Gen2内存芯片。

2024 年 HBM3 比重有望超越 HBM2e, 数据来源:TrendForce、开源证券研究所
根据TrendForce的数据,2023年主流需求从HBM2E转向HBM3,HBM3需求占比提升至39%,预计2024年市场需求占比将达60%。三星与SK海力士的HBM订单在2023年快速增加,HBM3规格DRAM价格上涨了5倍。三星电子和SK海力士计划明年大幅增加高端HBM芯片的产量,SK海力士还将在其清州工厂增加新的HBM生产线。
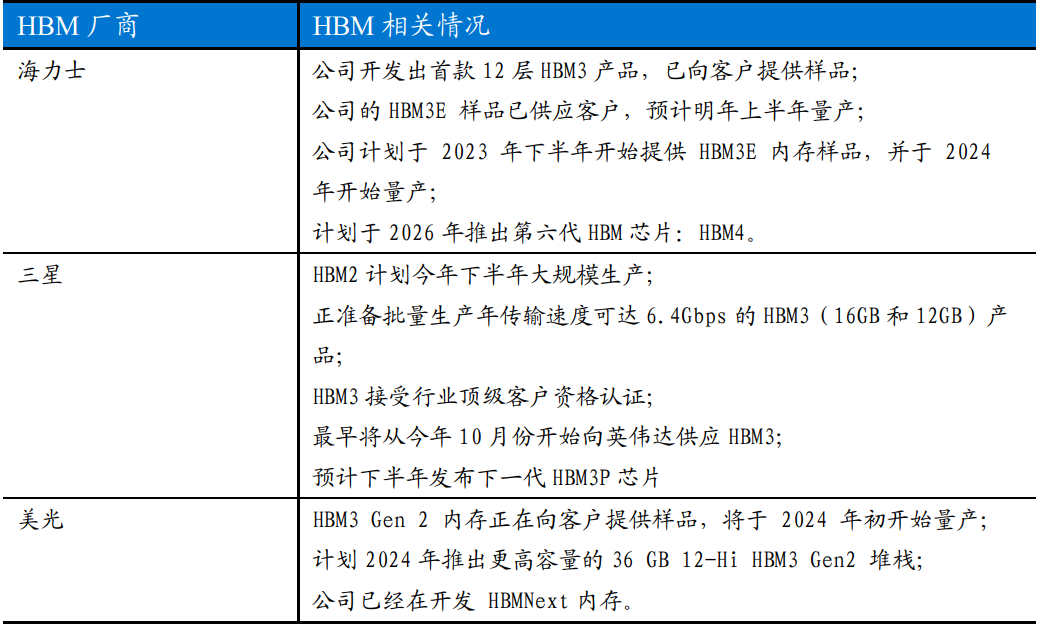
三大存储厂商 HBM 产品规划情况, 数据来源:公司官网,东吴证券研究所
先进封装的决胜时刻,HBM与chiplet技术融合
作为一种先进的存储器技术,HBM通过硅中介层与系统芯片(SoC)集成在一起。HBM技术的核心之一是TSV(硅通孔)技术,它允许多个芯片(通常是4-8层)通过硅穿孔电极垂直堆叠,实现芯片间的连接。随着市场对高容量存储器产品需求的增加,预计未来可能需要采用更多层次的多芯片堆叠技术,例如12-16层甚至更高的堆叠技术。这种堆叠技术可以进一步提高存储器的容量和性能,满足市场不断增长的需求。

应用于主流 GPU 的 HBM 内存技术持续升级,资料来源:英伟达官网,AMD 官网,中银证券整理
SK海力士是在HBM技术应用方面的先驱之一。2021年,海力士成功开发出全球首款12层堆叠HBM3 24GB产品,并在2022年实现量产。该产品采用了混合键合(HB)技术,去除了芯片间的填充物,使其直接连接到铜电极上,实现了更高的堆叠层数。海力士还在与包括Nvidia在内的多家无晶圆厂公司讨论HBM4的集成设计方法,预计将在台积电生产,使用晶圆键合技术将HBM4器件安装在逻辑芯片上。长江存储也采用了混合键合HB技术。他们创新地在两片晶圆上分别制造存储阵列和外围控制电路,然后通过HB技术将两片晶圆键合在一起,这一关键技术的应用使得3D NAND闪存的生产成为可能。
目前,HBM技术与chiplet技术的发展路径正逐渐拟合。SK 海力士正在与包括 Nvidia 在内的多家无晶圆厂公司讨论其 HBM4 集成设计方法。SK 海力士和 Nvidia 很可能会从一开始就共同设计该芯片,并在台积电生产,台积电还将使用晶圆键合技术将 SK 海力士的 HBM4 器件安装在逻辑芯片上。为了使存储器和逻辑半导体在同一芯片上作为一个整体工作,联合设计是不可避免的。
海力士提出的HBM4结构将I/O直接构建为die-to-die的接口,这正是chiplet的核心工艺。Die-to-die技术特别适合于存储和逻辑电路的连接,目前可见的chiplet方案通常是SRAM和CPU的堆叠或是大芯片方案的分区应用。如果海力士能成功地将大容量堆叠应用到GPU上,这将是一个领先的尝试,并可能成为chiplet技术发展的关键推动者。
日月光推出的VIPack™先进封装平台旨在提供高密度水平和垂直互连解决方案,适用于高效能运算、AI、机器学习等应用。此外,他们的FOCoS-Bridge平台作为六大核心封装技术支柱之一,能够实现高密度芯片对芯片连接、高I/O数量和高速信号传输。这些技术已在大型高效能封装体中通过桥接连接整合多个ASIC和HBM元件,并且支持多种串列和平行接口标准,如XSR、BOW、OpenHBI、AIB和UCIe,实现晶片对晶片的高频宽、低延迟互连。这些进展预示着日月光及其他先进封装技术领导者将在市场上扮演越来越重要的角色,特别是在满足全球AI高算力芯片应用需求方面。

全球部分先进封装解决方案(2D/2.5D/3D),来源:CEIA 电子智造,李杨《先进封装与异构集成》,信达证券研发中心
在先进封装技术的决胜时刻,产业链的变化已经非常明显。例如,日月光最近在与Nvidia和TSMC讨论CoWoS产能外移的问题,目标是增加同样面积下的晶体管密度和数据传输量。这种合作可能使得日月光能够避免后续成熟封装工艺的重复建设,同时帮助Nvidia解决CoWoS产能不足的问题,促进先进封装技术的发展。
随着HBM4的设计成熟,Chiplet技术的发展将更加顺畅。Chiplet本质是类似于SoC的复用IP模式,存储厂和TSMC能找到共同点,例如,合作以免相互竞争。AMD的2.5D或3D主要堆叠SRAM,但现在海力士携带最好的DRAM和HBM与TSMC的最佳5nm工艺合作,预示着Chiplet技术的重大进步。如果HBM+Chiplet应用普及,对球铝的需求可能会达到1000吨。封装前道的散热主要依赖材料和die堆叠,die越大、层数越多、体积越大,则材料使用量越多。HBM4方案可能会导致对球硅和球铝的大量需求。
总结:HBM比台积电更重要?
在AI时代,HBM已成为一项关键技术,它的出现和发展对传统存储技术构成了重大挑战,同时为未来人工智能和深度学习应用的发展提供了强大的基础支持。随着数据量和计算量的不断增长,超越现有DDR/GDDR带宽瓶颈的HBM可能成为解决存储问题的唯一方案。
11月14日,英伟达发布的NVDA H200显卡进一步加强了这种趋势。得益于HBM3e的搭载,H200显卡拥有141GB的内存和4.8TB/秒的带宽。在GPU架构无需调整的情况下,其推理速度达到了前代产品H100的两倍。HBM3E是一种基于3D堆叠工艺的DRAM存储芯片,AI服务器对其需求强烈。在摩尔定律放缓、GPU核心利用率不足的背景下,对高带宽存储的需求反而成为了性能提升的瓶颈,HBM因此成为破局的关键。当前H200搭载的HBM3e为海力士新一代产品,明年三星和美光也有望同步量产,标志着新一轮行业趋势的到来。
HBM的使用采用了Chiplet技术,其中关键的材料包括TSV(穿透硅孔)和LMC(液态塑封料)。随着HBM堆叠层数的增加,液态塑封料(LMC)、颗粒状塑封料(GMC)、TSV电镀液等材料的需求也随之增长。同时,为了提高HBM的IO密度,需要增加每层芯片的TSV通孔数量,这也对电镀液等材料提出了更高的要求。
笔者认为,从经济角度来看,HBM技术的发展和应用对于相关企业来说,意味着卖价的提升和利润的增加。尽管生产成本变化不大,但卖价的提高使得利润回到正值。海力士和三星等大型原厂正在对HBM的产能进行调整,以匹配当前AI领域的需求。这种产能调配也带来了较高的毛利。由于各家企业现在都在减少普通产品的产能,转而增加HBM等高性能产品的生产,这导致供应量的减少,进而推动了产品价格的上升。因此,HBM技术不仅在技术层面上对AI和深度学习的发展起到了推动作用,也在经济层面为相关企业带来了显著的利益增长。
最后,NVDAH200的发布揭示了算力下一步提升路径。某位存储厂商高管对笔者表示,“H200证明HBM比台积电更重要”。英伟达证明了就算不添加更多CUDA核或超频,只增加更多的HBM和更快的IO,即便保持现有Hopper架构不便,依然可以实现相当于架构代际升级的性能提升。

 器件型号:ATXMEGA128D4-AUR
器件型号:ATXMEGA128D4-AUR
 器件型号:AT90CAN128-16MUR
器件型号:AT90CAN128-16MUR
 器件型号:MCIMX535DVV1C
器件型号:MCIMX535DVV1C



.jpg?x-oss-process=image/resize,m_fill,w_400,h_298)




